
OpenAI Releases GPT-OSS 20B and 120B: A New Era for Open-Weight Reasoning Models
Local LLMs Are About To Get An Upgrade
OpenAI has just released its first open-weight, commercially licensed set of local LLM models since GPT-2 which has the potential to change everything for local LLM deployment.
Previously, OpenAI’s models have been closed in its interface (or API) meaning that to use the most powerful models for task based agent setups this had to be done through accessing the API or creating custom GPTs.
This can have its downsides for data integrity and sovereignty (particularly if you need to process data in the UK or EU).
However, with new open-weight models released from OpenAI – this now allows us to deploy powerful, fine-tuned LLM models locally and privately.
What Are GPT-OSS 20B and 120B?
These models are designed for reasoning, structured output, function calling, and chain-of-thought tasks, and come with detailed documentation, performance benchmarks, and safety assessments.
Both models use a Mixture of Experts (MoE) architecture, meaning only a subset of parameters are active during inference, keeping compute requirements lower while maintaining output quality.
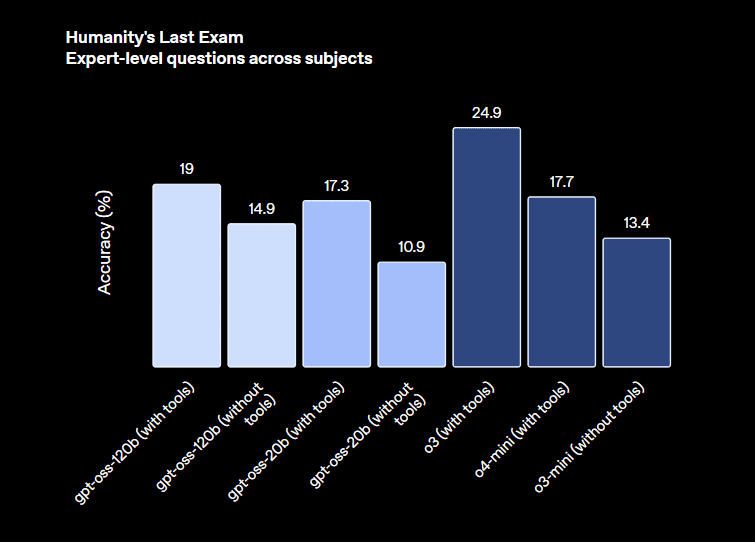
To put it simply, both of these models can compete with closed models including o3-mini and o4-mini comparably – with 120B being the more powerful model (and requiring a powerful hardware setup)
Let’s take a look at the models in detail:
GPT-OSS 20B
- 20.9 billion total parameters
- 3.6 billion active parameters per token
- 24 transformer layers
- 32 experts (2 active per forward pass)
- Can be run on a single 16GB GPU (with quantisation)
- Delivers performance comparable to OpenAI’s o3-mini model
- Ideal for on-device use, fast inference, and private deployment
GPT-OSS 120B
- 116.8 billion total parameters
- 5.1 billion active parameters per token
- 36 transformer layers
- 128 experts (4 active per forward pass)
- Requires an 80GB H100 GPU or multi-GPU setup for FP16 inference
- Matches or exceeds OpenAI’s o4-mini on reasoning and coding benchmarks
And, some of the more technical benchmarks:
Performance and Benchmarks
OpenAI has benchmarked the GPT-OSS models across a range of evaluation sets:
- SWE-Bench: GPT-OSS 120B performs extremely well in software engineering reasoning tasks
- MATH, AIME, GPQA: Strong results in chain-of-thought and symbolic reasoning
- HumanEval: High coding accuracy on Python tasks
- MMMLU (Multilingual): 120B holds up well across 14 languages
- HealthBench: Outperforms o1 and rivals o3/o4-mini in expert-domain tasks
While the 20B model trails behind its larger counterpart on some general language benchmarks, it holds up impressively well in core reasoning and logic-based tasks, especially given its hardware footprint.
Why This Matters
Open-weight models are crucial for organisations and businesses that need:
- Data sovereignty (e.g., processing in the UK/EU) – Particurlarly relevant for compliant based organisations e.g. Mortgage Brokers, Financial Services, Healthcare, and sensitive information.
- Private deployments with no reliance on external APIs – Can guarantee uptime dependent on local hardware infrastructure.
- Lower inference costs via local or edge deployment – Cuts overhead costs for accessing expensive APIs or cloud costs.
- Full control over fine-tuning and embedding – Fine-tuned models bespoke to your own business services and language.
Until now, OpenAI’s models have been locked behind hosted APIs. This makes data privacy, latency-sensitive tasks, or local AI agent development more difficult (or costly). The release of GPT-OSS 20B and 120B changes that.
We’ve previously written about the Advantages and Disadvantages of Local LLMs vs Cloud-Based LLMs, with this new release only amplifying the use-cases for local LLM deployment.
Consider a Mortgage Broker who deals with sensitive financial transaction data, personal information such as payslips, ID documents and more, alongside bespoke and technical language. Previously, such a business may have had to pay thousands to have a custom LLM developed to host on-site, or have an agreement with OpenAI on an Enterprise plan for zero data retention and data sovereignty.
However, this is not always enough. Now, with the ability to host a local OpenAI model that is comparable to o4-mini, that organisation can fine-tune their own custom large language model and deploy it in-house for a relatively low investment of hardware. A custom, private LLM that understands their business language, technicalities and has the ability to perform agent based tasks that would have previously required sending their private data to US servers or paying significant amounts for custom LLM development.
Any compliance based business from financial services, healthcare, dental clinics and organisations requiring enhanced privacy can now download OpenAI’s open-weight models, fine-tune them, and given sufficient hardware – run efficient agent based workflows in a private, secure LLM.
Final Thoughts
The GPT-OSS 20B and 120B models represent a clear step forward in making high-performance language models available for private use.
- The 20B model opens up powerful local inference for businesses, startups, and researchers.
- The 120B model brings top-tier reasoning capability to SMB and enterprise-grade workloads with full ownership and security.
These models can now be embedded in secure internal systems, deployed on-site, or fine-tuned to handle domain specific tasks – all without sending data out of the country.
If you’re building AI-powered agents, RAG systems, customer support workflows, or internal tools, this release opens the door to full-stack, open-weight LLM deployment with no vendor lock-in.
At flowio – we support businesses in developing their own private, local LLM systems, and can fine-tune custom LLM models. Unsure where to start? Talk to us for more information on training and deploying a local LLM within your business that can run your AI agent workflows.
About the author

Malcolm Gibb — Founder & CEO // flowio
Hi, I'm Malcolm — Founder of flowio. I founded flowio after 15 years of leading performance marketing agencies. flowio exists to help businesses combine AI, automation and smart development solutions to solve critical business challenges. The content you read here is written by myself and based on experiences, insights and topical content from working with our clients.
Looking to speak to an expert to help your business scale? Whether you are starting your journey into AI strategy or need a full done-for-you automation solution, book a chat with us to discover where the opportunity exists.